(一)隐私分类
隐私分类 | 说明 | 保护目标 | 保护方法 | |
1 | 身份隐私 | 用户数据分析识别出特定用户真实身份信息 | 降低攻击者从数据集中识别出某特定用户的可能性 | 对公开数据或信息进行匿名化处理 |
2 | 属性隐私 | 属性信息:描述个人用户属性特征(年龄、性别、薪资、购物史等) | 对用户相关属性信息进行安全保护处理 | |
3 | 社交关系隐私 | 用户不愿公开的社交关系信息 | 对社交关系节点匿名处理,使无法确认特定用户社交关系 | |
4 | 位置轨迹隐私 | 用户非自愿公开的位置轨迹数据及信息 对用户位置轨迹数据进行分析,可推导出用户隐私属性 | 对用户真实位置和轨迹数据进行隐藏或安全处理,不泄露用户敏感位置和行动规律给恶意攻击者 |
(二)隐私保护目标
通过对隐私数据安全修改处理,使修改后数据可公开发布而不会遭受隐私攻击。修改后数据要在保护隐私前提下,最大限度保留原数据使用价值
(三)隐私保护方法
方法 | 说明 | |
1 | K-匿名方法 | 对数据所有元组泛化处理,使其不再与任何人一一对应,且泛化后每条记录都要与至少k-1条其他记录完全一致 |
缺点:易遭受到一致性攻击 改进:L-多样性方法。在任意一个等价类中每个敏感属性(如“疾病”)至少有1个不同值 | ||
2 | 差分隐私方法 | 对保护数据集添加随机噪声构成新数据集,使攻击者无法通过已知内容推出原数据集和新数据集差异 |
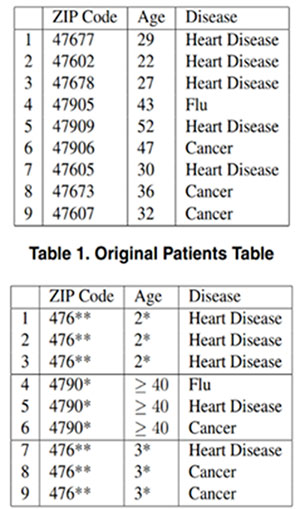
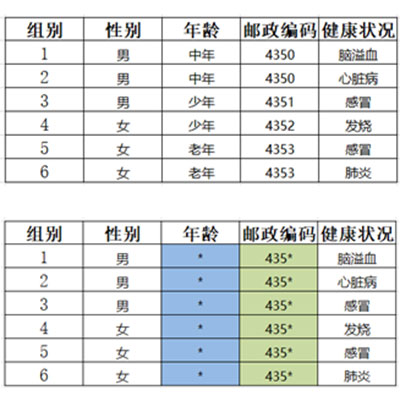
(1)K-匿名方法
标识符(explicit identifiers):可以直接确定一个个体,如id、姓名等。
准标识符集(quasi-identifler attribute set):可以和外部表连接来识别个体的最小属性集,如通过 {省份,年龄,性别,邮编}这4个属性确定一个个体。
(2)差分隐私方法
是目前基于扰动的隐私保护方法中安全级别最高的方法。
【理解1】假设现有一个婚恋数据库,2个单身8个已婚,只能查有多少人单身。刚开始时查询发现,2人单身;现在张三跑去进行了婚姻登记,再查询,发现3个人单身。所以张三单身。张三作为一个样本的出现,使得攻击者获得了奇怪的知识。而差分隐私要做的就是使攻击者获得的知识不会因为这些新样本的出现而发生变化。
【理解2】查询某大型医疗数据库,如果A的信息在数据库中。我们可以查询有多少人患糖尿病,假如有100个人,然后条件查询,有多少不叫A的人患糖尿病,假如有99个人,经过差分就得到了A患糖尿病。
(四)隐私保护技术措施
措施 | 说明 | 举例 | |
1 | 抑制 | 数据置空 | 不显示 |
2 | 泛化 | 降低数据精度来提供匿名性 | 年龄35→30 具体街道→城市或地区 具体年月日→月份或年份 |
3 | 置换 | 改变数据属主 | 考号代替真名 |
4 | 扰动 | 数据添加噪声(增删、变换)来破坏数据原始性 | 手机号135****1234 |
5 | 裁剪 | 敏感数据分开发布 | 密码分成几份 |
6 | 加密 | 阻止非法用户对隐私数据未授权访问和滥用 | 登录后解密数据 |
(五)泛化和扰动对比
- 目标不同:泛化主要通过降低数据精度来提供匿名性,而扰动则通过添加噪声或变换来破坏数据的原始性。
- 实现方式不同:泛化通常涉及选择更广泛的类别或范围来替换原始值,而扰动则包括添加随机噪声、数据增删、变换等多种技术。
- 应用场景不同:泛化在需要保持数据分析价值的同时保护隐私的场景中较为常见,而扰动则在需要严格保护数据隐私的场景中更为重要。